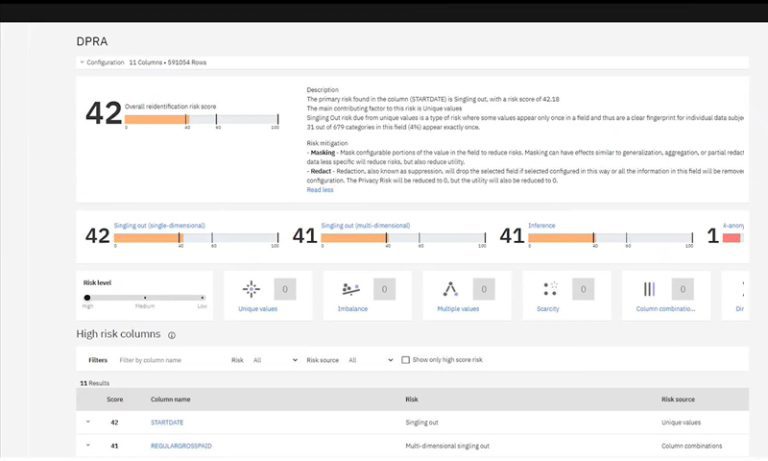
IBM and Trūata partner to help businesses assess privacy risk in data with advanced Fingerprint technology
Trūata has announced the launch of its partner solution with IBM to help organizations to understand the privacy risk in their data.

Trūata has announced the launch of its partner solution with IBM to help organizations to understand the privacy risk in their data.

Trūata, the privacy-enhanced data analytics solutions provider, has announced the availability of Trūata Calibrate in the Microsoft Azure Marketplace.

Trūata announces that the USPTO has granted patent approval for the company’s privacy risk quantification and mitigation system and method used in the Trūata Calibrate software solution..

The accelerated adoption of technological innovations to optimise every aspect of our lives not only generates large volumes of data around our activities but also heavily relies on this data. The potential benefits to be gained from the use of this data serves both individuals and organizations.

Trūata has announced the issuance of a new patent from the United States Patent and Trademark Office, further strengthening the foundations of its intellectual property.

Explore the potential of federated learning – secure data and protect privacy in an AI-driven world. Privacy and security concerns have led the charge for ML technology that can work in a way that preserves consumer privacy, which is why federated learning (FL) has gained such momentum.

Organizations that adopt a proactive, privacy-centric approach will be better positioned to manage regulatory risk.

Changed behaviours and accelerated digital transformation triggered by the pandemic have become catalysts for conversations surrounding data privacy and consumers are making their expectations known. Our Global Consumer State of Mind Report, which captured the views of 8,000 consumers across the globe found that people want to take back control of their digital selves.